
Aono, Masaki

| Affiliation | Department of Computer Science and Engineering |
|---|---|
| Concurrent post | Research Center for Agrotechnology and Biotechnology Research Center for Collaborative Area Risk Management (CARM) |
| Title | Project Professor |
| Fields of Research | Data Science / Multimedia retrieval and data management / Deep learning / Text mining |
| Degree | Ph.D. (Rensselaer Polytechnic Institute, USA) |
| Academic Societies | ACM / IEEE / IPSJ / IEICE / NLP / JSAI / Japan Database Society |
| aono@ Please append "tut.jp" to the end of the address above. |
|
| Laboratory website URL | https://www.kde.cs.tut.ac.jp/ |
| Researcher information URL(researchmap) | Researcher information |
Research
We have been focusing on 3D shape retrieval (from 3D query or from 2D images/sketches) as our unique research for more than a decade. We are boasting of the world top level search performance with our patented technologies.
Current research interests include multimedia (text, image, and video) retrieval, feature extraction, feature selection, classification, and automatic annotation.
Recently, we are concentrating on the application of deep learning to the above research fields. Some of the new research includes automatic annotation to images, 3D scenes.
We also start doing research on predicting who, what, when, and where of the given objects (e.g. images, long texts, short texts (e.g. tweets)), sometimes in accordance with Q & A and reading comprehension resarch.
Other related research topics of our interest includes text mining (e.g. sentiment analysis, opinion mining), data mining (e.g. time series data mining), and Web mining.
Theme1:Research on 3D Shape Retrieval, Shape Classification, Segmentation, and Automatic Annotation based on Supervised Learning
Overview
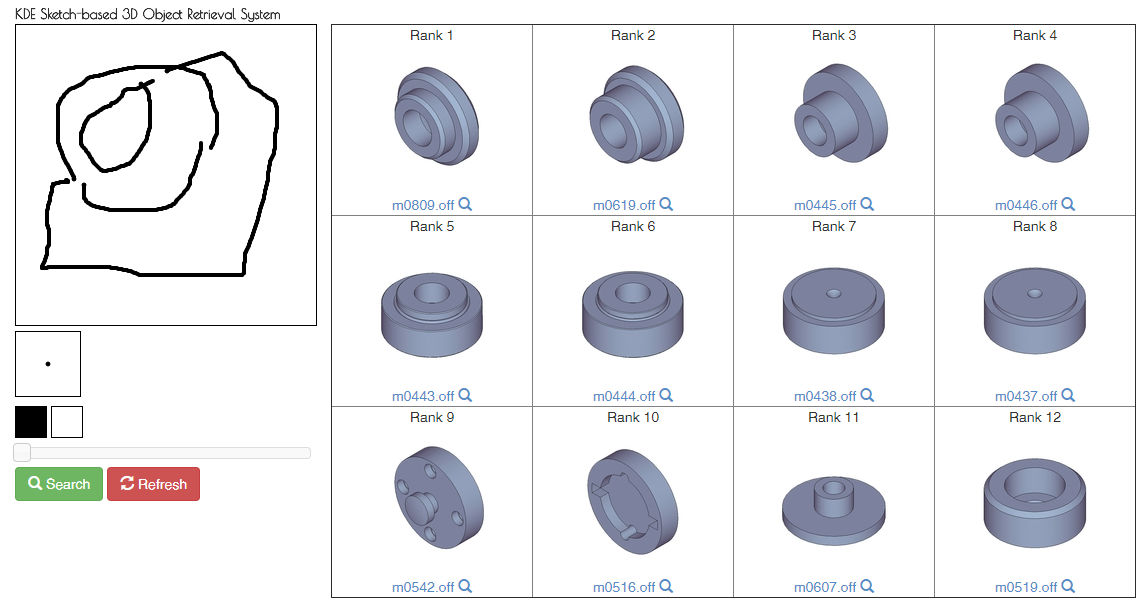 Fig.1 A sample 3D shape retrieval from 2D sketch
Fig.1 A sample 3D shape retrieval from 2D sketch3D shape models are in great use in a variety of industries ranging from mechanical CAD, flight simulator, architecture, civil engineering, to entertainment industries, education, and commercial films, and 3D movies. However, it is formidable to create each new 3D model from scratch, because making a 3D shape models is very time consuming and expensive task. To overcome these difficulties, we have developed a series of new technologies (where some of them are patented) to retrieve 3D shape objects with remarkable accuracy.
In addition to searching each 3D shape, we recently have embarked on
a research dealing with a collection of 3D objects called "3D scene", and introduced a deep learning approach to the 3D shape search and classification.
Selected publications and works
Shoki Tashiro, Atsushi Tatsuma, and Masaki Aono, Super-vector coding
features extracted from both depth buffer and view-normal-angle images for
part-based 3D shape retrieval, Multimedia Tools and Applications, Volume
76, Issue 21, pp. 22059-22076, November 2017, Springer,
DOI:http://dx.doi.org/10.1007/s11042-017-4801-z
Wataru Iwabuchi and Masaki Aono, 3D CNN based Partial 3D Shape Retrieval
Focusing on Local Features, Asia Pacific Signal and Information Processing
Association (APSIPA2018), pp.1523-1529, November 15th, Honolulu, Hawaii,
USA, 2018
Kazuma Hamada and Masaki Aono, 3D Indoor Scene Classification using Tri-projection Voxel Splatting, Asia Pacific Signal and Information Processing Association (APSIPA2018), pp.317-323, November 13th, Honolulu, Hawaii, USA, 2018
Keywords
Theme2:Plant Identification using Deep Learning
Overview
 Fig.2 Plant Identification System
Fig.2 Plant Identification SystemGive massive plant images taken in the field, we have been conducting research to identify the species of the plant, no matter what kind of images such as flower, leaves, a tree as a whole, and barks. We have used unique deep learning technologies behind the accurate identification. We believe this technology can be used for multiple potential applications including partial search and 3D scene retrieval.
Selected publications and works
World No.1 record in PlantCLEF2016 (international competition)
Siang Thye Hang, Atsushi Tatsuma, and Masaki Aono, Bluefield (KDE TUT) at LifeCLEF 2016 Plant Identification Task, LifeCLEF 2016 Workshop in Conference and Labs of the Evaluation Forum (CLEF2016), 10pp, September 6th, University of Évora, Portugal, 2016
Siang Thye Hang and Masaki Aono, Open World Plant Image Identification Based on Convolutional Neural Network, Asia Pacific Signal and Information Processing Association (APSIPA2016), 4pp, December 16th, Jeju, Korea, 2016
Keywords
Theme3:Automatic Annotation
Overview
 Fig.3 Semantic segmentation based on a query text
Fig.3 Semantic segmentation based on a query textGiven images, this research seeks new technologies to automatically generate appropriate annotations.
Selected publications and works
World No.1 record in ImageCLEF2014 in image annotation track.
Our paper was accepted by IJCAI2017, one of the top AI international conferences.
Ismat Ara Reshma, Md Zia Ullah, Masaki Aono, Ontology based Classification for Multi-label Image Annotation, The 2014 International Conference on Advanced Informatics: Concepts, Theory and Applications (ICAICTA 2014), 6pp, Best Paper Awarded, August 20th, Bandung, Indonesia, 2014
Ko Endo, Masaki Aono, Eric Nichols, Kotarou Funakoshi, An Attention-based Regression Model for Grounding Textual Phrases in Images, International Joint Conference on Artificial Intelligence (IJCAI2017), 7pp, August 25, Melbourne, Australia, 2017
Keywords
Title of class
Computer Programming B13610020 Compulsory (B3)
Introduction to Computer Architecture, B13530090 (B2)
Data Mining and Visualization, M23630080 (M1)
Web data engineering