
ここからコンテンツです。
AI-powered autonomous driving vehicle
Artificial Intelligence (AI) model that handles multiple perception and control tasks simultaneously in driving a vehicle safely in diverse environments Jun Miura and Oskar Natan
A research team consisting of Oskar Natan, a Ph.D. student, and his supervisor, Professor Jun Miura, who are affiliated with the Active Intelligent System Laboratory (AISL), Department of Computer Science and Engineering, Toyohashi University of Technology, has developed an AI model that can handle perception and control simultaneously for an autonomous driving vehicle. The AI model perceives the environment by completing several vision tasks while driving the vehicle following a sequence of route points. Moreover, the AI model can drive the vehicle safely in diverse environmental conditions under various scenarios. Evaluated under point-to-point navigation tasks, the AI model outperformed its rivals in this field in terms of drivability in a standard simulation environment.
Autonomous driving generally entails a complex system consisting of several subsystems that handle multiple perception and control tasks. However, deploying multiple task-specific modules is costly and inefficient, as numerous configurations are still needed to form an integrated modular system. Furthermore, the integration process can lead to information loss as many parameters are adjusted manually. With rapid deep learning research, this issue can be tackled by training a single AI model with end-to-end and multi-task learning techniques. Thus, the model can provide navigational controls solely based on the observations provided by a set of sensors. As manual configuration is no longer needed, the model can manage the information all by itself.
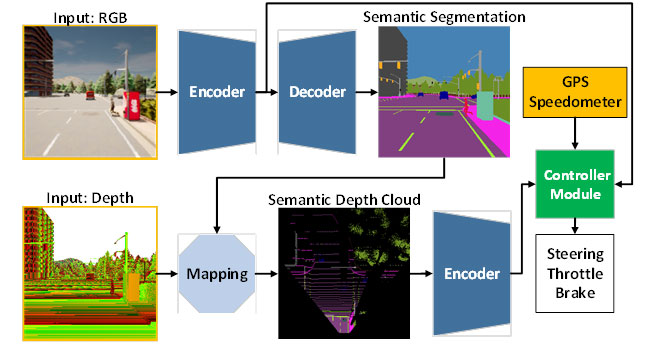
The challenge that remains for an end-to-end model is how to extract useful information so that the controller can estimate the navigational controls properly. This can be solved by providing a lot of data to the perception module so that the ambient environment recognition part of the model can learn sufficiently. In addition, a sensor fusion technique can be used to enhance performance as it fuses different sensors to capture various data aspects. However, a number of problems in model design and training need to be solved, including the increased computational complexity of handling large amounts of data, the need to design data preprocessing to combine different forms of information, and the need to balance the learning of multiple tasks.
In order to answer those challenges, the team proposed an AI model trained with end-to-end and multi-task manners. The model is made of two main modules, namely perception and controller modules. The perception phase begins by processing RGB images and depth maps provided by a single RGBD camera. Then, the information extracted from the perception module along with vehicle speed measurement and route point coordinates are decoded by the controller module to estimate the navigational controls. So as to ensure that all tasks can be performed equally, the team employs an algorithm called modified gradient normalization (MGN) to balance the learning signal during the training process. The team considers imitation learning as it allows the model to learn from a large-scale dataset to match a near-human standard. Furthermore, the team designed the model to use a smaller number of parameters than others to reduce the computational load and accelerate the inference on a device with limited resources.
Based on the experimental result in a standard autonomous driving simulator, CARLA, it is revealed that fusing RGB images and depth maps to form a birds-eye-view (BEV) semantic map can boost the overall performance. As the perception module has better overall understanding of the scene, the controller module can leverage useful information to estimate the navigational controls properly. Furthermore, the team states that the proposed model is preferable for deployment as it achieves better drivability with fewer parameters than other models.
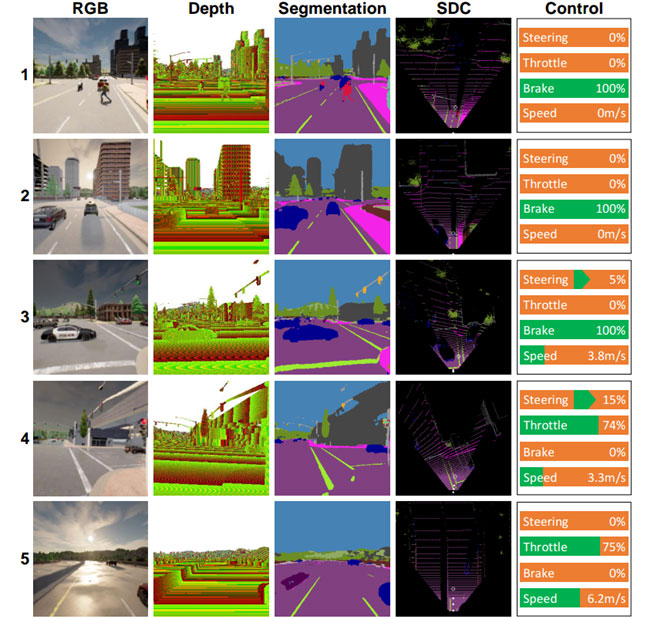
The team is currently working on modifications and improvements to the model so as to tackle several issues when driving in poor light, such as at night, in heavy rain, etc. As a hypothesis, the team believes that adding a sensor that is unaffected by changes in brightness or illumination, such as LiDAR, will improve the model’s scene understanding and result in better drivability. Another future task is to apply the proposed model to autonomous driving in the real world.
Reference
O. Natan and J. Miura, “End-to-End Autonomous Driving with Semantic Depth Cloud Mapping and Multi-Agent,” in IEEE Transactions on Intelligent Vehicles, vol. 8, no. 1, pp. 557-571, Jan. 2023.
https://doi.org/10.1109/TIV.2022.3185303
最新AIによる自動運転
道路シーン解析と運転制御を同時に行う新たなAIが多様な環境での安全な自動運転を実現三浦 純、オスカー ナタン
豊橋技術科学大学 情報・知能工学系 行動知能システム学研究室の三浦純教授と大学院博士後期課程2年のOskar Natanは、道路シーン解析と運転制御を同時に行う新たなAIモデルを開発しました。このAIモデルは、カメラからの入力情報を解析して周囲の状況を認識すると同時に、進むべき経路を計算し、車を誘導します。本モデルは、標準的な自動運転シミュレーション環境での実験を行い、さまざまな状況下で安全な自動運転を行うことができ、他の最新の手法より優れた運転性能を示すことができました。
自動運転システムは、複数のシーン認識や運転制御処理を行う必要があり、一般に複雑なシステムとなります。まず個々の処理を実現し、それらを組み合わせるアプローチでは、個々の処理の調整や最適な組み合わせの探索が必要となり、システム開発に時間がかかります。そこで、最新の深層学習技術を利用し、複数の処理を同時に学習するマルチタスク学習手法と、入力の画像データから出力の運転制御量を直接計算するEnd-to-end方式を用いた単一のAIモデルで自動運転を行う手法を開発しました。提案手法では、複数処理の設計や組み合わせを考慮する必要はなく、また、学習は1つのモデルに対してのみ行うだけで済みます。
そのようなAIモデルの設計において課題となるのは、最終的に必要となる運転制御量の計算に役立つ情報をどのようにして得るかです。そのためには、複数センサ情報を組み合わせて多様な情報を得るためのセンサフュージョン技術を利用するとともに、モデル中の周囲環境認識部が十分学習できるように多くのデータを与えることが基本的なアプローチになります。しかしながら、大量のデータを扱うための計算量が増大すること、異なる形の情報を組み合わせるためのデータ前処理の設計が必要になること、そして、複数種類の処理の学習をバランスよく進めることなど、モデルの設計と学習における多くの問題を解決する必要があります。
そこで、研究チームは、次のようなシーン認識部と運転制御部からなるAIモデルを提案しました。シーン認識部は、1つのRGB-Dカメラから得られるカラー画像と距離画像を処理します。運転制御部は、シーン認識部の結果、及び車の速度と目標とする移動経路の情報を得て、運転制御量を計算します。各部のバランスの取れた学習を行うために、修正勾配正規化法(MGN)というパラメータ修正手法を用い、シミュレーション環境上で収集された多数のデータを用いて模倣学習を行います。作成したモデルのパラメータ数は他のモデルよりかなり少なく、性能の限られた計算機でも十分に機能します。
自動運転に関する標準的なシミュレーション環境であるCARLA環境で実験を行い、他の最新の手法に比べ、小規模のモデルであるにもかかわらず、高い運転性能が得られることを示しました。また、カラー画像と距離画像を組み合わせて作成した鳥瞰地図を利用することで、運転に必要な情報をうまく取り出すことができ、運転性能に極めて有効であることも示しました。
研究チームは現在、夜間や強い雨など照明条件が悪い環境下での運転性能向上に取り組んでいます。そのために、照明条件に左右されないレーザ距離センサなどの新たなセンサ情報を追加することにより、シーン認識と運転制御の性能を向上させることを考えています。また、実環境での自動運転への適用も今後の課題です。
Researcher Profile

| Name | Jun Miura |
|---|---|
| Affiliation | Department of Computer Science and Engineering |
| Title | Professor |
| Fields of Research | Intelligent Robotics / Robot Vision / Artificial Intelligence |

| Name | Oskar Natan |
|---|---|
| Affiliation | Department of Computer Science and Engineering |
| Title | Doctor course student |
| Fields of Research | Intelligent Robotics / Robot Vision / Artificial Intelligence |
ここでコンテンツ終わりです。