
梅村 恭司(うめむら きょうじ)

| 所属 | 情報・知能工学系 |
|---|---|
| 職名 | 教授 |
| 専門分野 | 情報工学 |
| 学位 | 博士(工学) 東京大学 |
| 所属学会 | 情報処理学会 / 情報電子通信学会 / ソフトウェア科学会 / 計量国語学会 / ACM / ACL |
| umemura@ ※アドレスの末尾に「tut.jp」を補完してください |
|
| 研究室web | http://www.ss.cs.tut.ac.jp/ |
| 研究者情報(researchmap) | 研究者情報 |
研究紹介
文字列の計数アルゴリズムや,統計的に関係を見つけることに独自の技術を保有しています。データはコンピュータの中では文字列として表現されていると見なすことができます。本研究室では,文字列のなかに統計的な構造を見つけたり,文字列がならんでいる規則を情報量の観点からモデル化することを行っています。これを,文字列処理だけでなく,センサネットワークの応用も行っています。
Kyoji Umemura, Kenneth Church, Substring Statistics, LNCS, vol.5449 Springer, pp. 53-71, 2010
尾上徹、平田勝大、岡部正幸、梅村恭司,文字列を特徴量とし反復度を用いたテキスト分類,自然言語処理, Vol.17, No.1, pp78-97
テーマ1:統計処理による関連語の抽出システム
概要
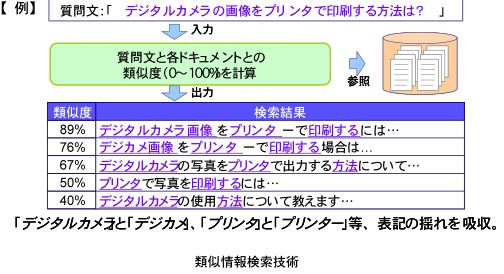 関連語の検出を組み込んだシステムの機能
関連語の検出を組み込んだシステムの機能文字情報を検索したり,分析したりするときに,表面上は異なる単語でも,意味の上では関連のある単語を特定したいという問題があります。意味をコンピュータで直接処理をすることは難しい問題ですが,同じように使われるものという分析は,コンピュータで実行できるものです。同じように使われるときには,その二つは意味の上で関連があるものというアプローチで,文字情報から関連のある単語列の組みを取り出すシステムを開発し,その性能を改良しています。ありとあらゆる単語列の組みから,同じように使われる組みを選ぶという問題ですが,単純に解こうとするとコンピュータの処理時間がながくなりすぎるという問題があります。この処理の高速化が研究室の独自技術です。研究室では,このような統計的な計算をするコンピュータのために,メモリが多めのコンピュータをそろえています。この技術があっても,「同じように使われる」ということを,何らかの数式で実現しないとコンピュータで処理できません。このような数式を考えるときには,グループでの議論や文献の調査が重要です。そのため,議論の結果をコンピュータに記録しながら,過去の議論をみながらさらに議論を重ねるような設備も工夫しています。成果は,共同研究先の企業から製品となって販売されています。
キーワード
テーマ2:情報量をもとにしたセンサーネットワークでの異常検知
概要
 人感センサノードのプロトタイプ
人感センサノードのプロトタイプセンサーの出力が「いつもとちがう」ということをコンピュータが判定するために,センサー出力を記号列として表現して,そこでの言語モデルを構築し,その言語モデルとデータとの関係を判定するという処理を行っています。これによって,通常と違う状態になっていることを検出するときに,センサーの設定を簡素化し,システムが状況に応じて適応していく処理を可能としています。
キーワード
担当授業科目名(科目コード)
プログラミング言語 ( 142143) / 論理数学 ( 142112) / 情報伝送工学特論 ( 242035) / 情報ネットワーク ( 132114) / 情報ネットワーク ( 141106)
その他(受賞、学会役員等)
総務省戦略的情報通信研究開発推進制度により,他の研究室,機関と協力して,「インターユビキタスネットワーク情報基盤の研究」を実施しています。